In a previous article I introduced the idea of modifying text between copy and paste in Linux, using a 'CoPa' script based on the xclip utility. Please refer to that article for the basic ideas.
Here I demonstrate two handy CoPa scripts for spreadsheets, and a simple coder/decoder for (very!) low-level encryption of email text and other messages.
#Copy/paste in Calc
LibreOffice Calc allows X selection copy/paste within a single worksheet. Just highlight a group of cells, move the cursor to a group of blank cells, middle-click, and the highlighted cells are pasted in the new location (first screenshot).
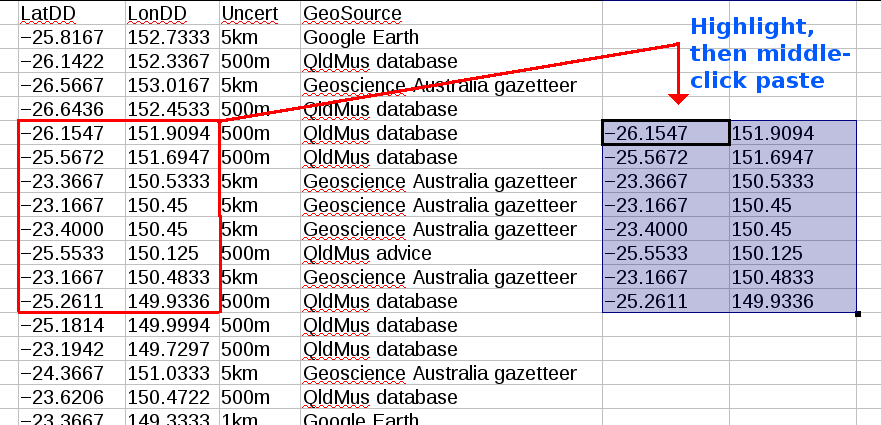
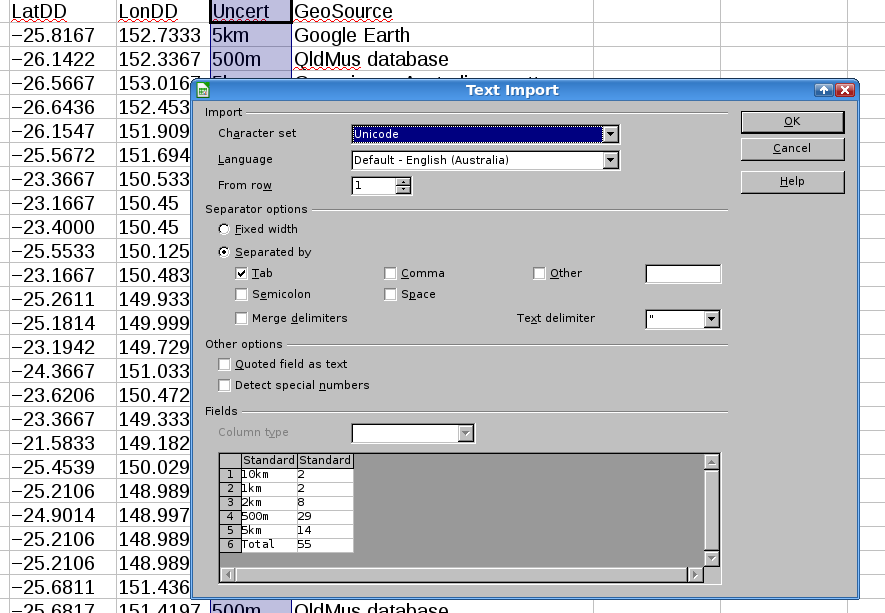
This kind of copy/paste doesn't operate between worksheets or between workbooks, however. Furthermore, if you empty the X selection clipboard, do something with its contents, and reload that clipboard (as we're going to do with our CoPa scripts), Calc insists on opening its text import dialog (second screenshot). This adds another step to CoPa in Calc: pressing 'Enter' on the keyboard when the dialog appears, or clicking on the dialog's 'OK' button.
#Get frequencies of non-blank values
To work our first script, just highlight a column, launch the script, middle-click in a blank cell and say 'Yes' to the text import dialog. The result is a list of the non-blank values in the column and their frequencies, plus a total (screenshot 3). You can, of course, also middle-click paste the results into a text program; the values and their frequencies are separated by a tab.
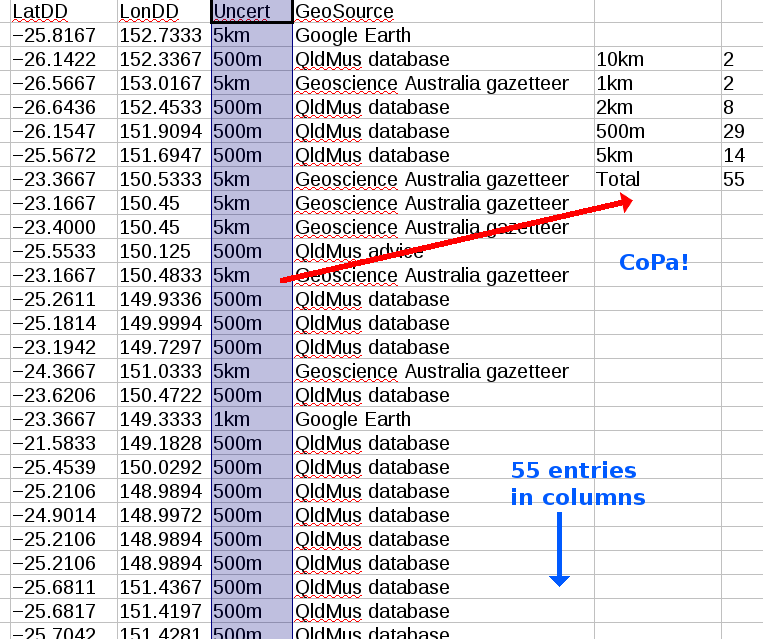
Here's the script:
#!/bin/bash
xclip -o \
| sed '1d' \
| sed '/^$/d' \
| sort \
| sed 's/ /\^/g' \
| uniq -c \
| awk 'BEGIN {OFS="\t"} {print $2,$1} { SUM += $1} END {print "Total",SUM}' \
| sed 's/\^/ /g' \
| xclip -i
How it works: The X selection clipboard contents are first sent to a sed command which deletes the first line, namely the column's field name. The next sed command removes any blank lines (blank cells in the highlighted column). The text is then sent to sort, which sorts the entries, and then to a sed command which replaces any blanks in a string value with the dummy character ^ (I'll explain why in a moment). The resulting list of values is sent to uniq with its '-c' option, which does the grunt work of finding unique values and counting how many times they occur. These numbers are printed before each unique value, separated from the value by a space. The list is next sent to AWK, which prints the list back to front, i.e. value first, then frequency, separated by a tab. AWK also totals up the frequencies and appends that total to the end of the list. The list is then sent back to sed to have those dummy ^ characters replaced by a space. If we hadn't done this, then uniq would only have printed the first item in a string which has space separators, like 'Mr' instead of the full 'Mr John Smith'. Finally, the list is loaded into xclip for pasting.
#Do data conversions
I often need to convert latitude/longitude values in a spreadsheet from degree-minute-second format to decimal degrees. I could do this with a spreadsheet formula, but CoPa is cooler (fourth screenshot).
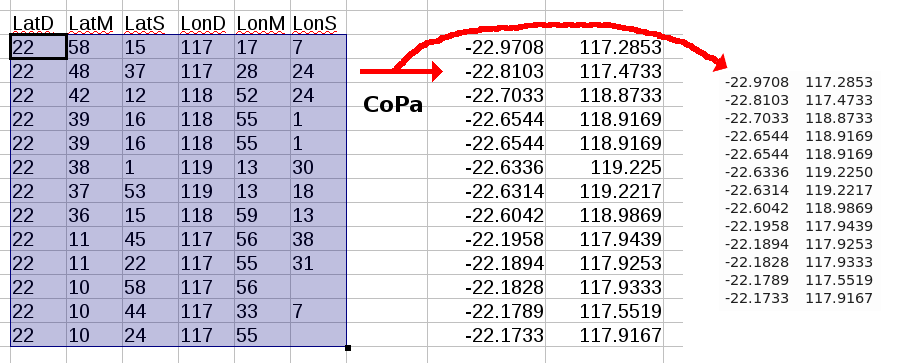
Here's the script:
#!/bin/bash
xclip -o \
| sed 's/\t\t/\t0\t/g' \
| awk '{latDD = -($1 + $2/60 +$3/3600) ; lonDD = ($4 + $5/60 +$6/3600)} {printf ("%.4f\t%.4f\n", latDD, lonDD)}' \
| xclip -i
How it works: The sed command replaces any blank values ('cells') in the latitude/longitude group with zero before passing the list to AWK. AWK sees the list as lines with six values, which it numbers $1, $2, etc; AWK then does the conversion to decimal degrees. (Note that I live in Australia, so my decimal degree latitudes are negative and my longitudes are positive.) AWK then prints those values, in this case to four decimal places. You can see all four places in the text-pasting in the screenshot above; Calc only shows non-zero last places in decimals.
#A secret message coder/decoder!
And now for something completely silly, a cryptographic script for disguising the contents of an email, just like you wanted when you were a kid. The sender uses the coder CoPa script:
xclip -o \
| tr '[:upper:]' '[:lower:]' \
| tr 'abcdefghijklmnopqrtsuvwxyz' 'cfstoqzwpiurlnamkyjhgdvbex' \
| xclip -i
which transforms a message into gobbledygook by transposition (fifth screenshot):

The receiver uses this CoPa script to reverse the transposition and decode the message:
#!/bin/bash
xclip -o \
| tr 'cfstoqzwpiurlnamkyjhgdvbex' 'abcdefghijklmnopqrtsuvwxyz' \
| xclip -i

How it works: To keep the script simple, the message has all its capital letters transformed into lower case using the first tr command. The next tr command replaces each letter of the alphabet with another, taken from a permutation of the 26 letters. The decoder script simply reverses the transformation.
There are an awful lot of paired coder/decoder scripts like the one above, each using a different permutation of the alphabet. I built this particular permutation in a terminal using the rather neat commands
shuf -e a b c d e f g h i j k l m n o p q r s t u v w x y z | tr -d '\n'
For more on shuf, see its Linux man page. It generates a list of permuted values from the spaced letters, and the tr -d '\n' command collapses the list into a simple string.