This is an odd story. It began about 10 years ago, when I needed a database, then it moved back 30 years, and now I don't need one.
Confused? I promise to explain, and also to demonstrate some surprisingly useful command-line tricks.
#What the heck is a foreign key?
First, let me show you why I needed a database, or thought I did. I'll use a made-up, much simplified example. Imagine you run a hotel, and you record each guest's contact details in a table of records (first screenshot).
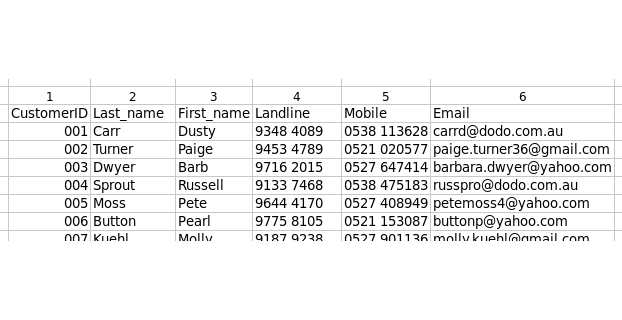
The first field of your table has a unique identifying number for each guest (001 ->), making that field what database people call a 'primary key'.
You also have a table of bookings (second screenshot). Each booking has a unique identifying number in the BookingID field, which is the primary key for that table. But rather than include the name and contact details for each guest in the bookings table, you just put in a CustomerID field containing the unique number which had been assigned to that guest in the first table.
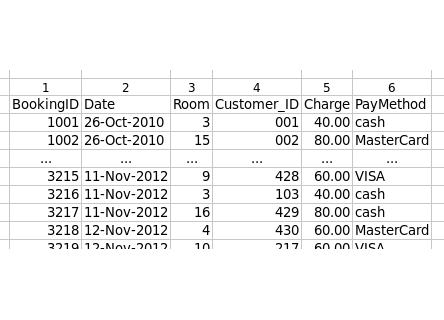
The CustomerID field in the bookings table is what's technically known as a 'foreign key'. It relates information in the bookings table to information in the guests table, through that first table's primary key.
#...and that means a database, right?
Suppose the guest who stayed with BookingID 3217 left a jacket behind, and you wanted to ring the guest's mobile phone number. You would look in the BookingID 3217 record for the CustomerID number, see that it's 429 (second screenshot), then go to the guests table, look up CustomerID 429, and find the mobile number.
Well, that's exactly the sort of query (what mobile number goes with BookingID 3217?) that relational databases were designed to handle. The database software does the looking-up for you. Just feed it the tables, tell it which field is related to which between tables, and you're ready to run your hotel – or in my case, a huge mass of biodiversity data. Database software also stores the tables for you and allows you to edit and update them, either separately or across related tables.
My problem 10 years ago was that I didn't want the database to store the tables. I wanted them in spreadsheet software, because spreadsheets are easier to use and are capable of more sophisticated data manipulations than most databases can do.
So I managed my tables in spreadsheets, and when I wanted to do a 'relational' query I exported the tables as CSV or tab-separated text files. I then created a new database in a relational database program, imported the text files, did the query, exported the result as a new text file, and opened that query result in my spreadsheet application.
In those days my computer ran Windows, and my tables were kept in Microsoft Excel. When I needed to join or query tables, I exported them from Excel as CSV files and imported them into FileMaker Pro, a proprietary 'desktop' database application.
Time passed, and I abandoned Windows for Linux. The tables moved to Gnumeric spreadsheets. The 'desktop' database was OpenOffice Base at first, then Kexi, then SQLite on the command line. SQLite was the fastest of the three and the easiest to use, but it needed a working knowledge of the SQL databasing language. (A good place to learn or refresh SQL basics is w3schools.com.)
#The database vanishes
Last year I began learning AWK, a simple command-line language that was designed for manipulating lines of text broken into fields. It wasn't long before the penny dropped. Hey! My tables are really only lines of text broken into fields! And I quickly discovered that AWK could do almost anything with that kind of text file. Did I really need a database at all?
No, not for my usual queries. All I had to do was number the fields in my tables (see the two screenshots above), because AWK uses field numbers, not field names.
Here's a real example. I have a huge 'events' table with details of where, when and by whom some biological specimens were collected. The latest version is always called Events_today.txt, and the primary key field is field 1. AWK is used for two different jobs in the following shell script, which on my desktop is launched by clicking an item on a drop-down panel menu:
#!/bin/bash
zenity --title="Event plotter" --entry --text="Enter Lat N limit (-)" > /tmp/combo
zenity --title="Event plotter" --entry --text="Enter Lat S limit (-)" >> /tmp/combo
zenity --title="Event plotter" --entry --text="Enter Lon W limit" >> /tmp/combo
zenity --title="Event plotter" --entry --text="Enter Lon E limit" >> /tmp/combo
A=$(awk 'FNR == 1 {print}' /tmp/combo)
B=$(awk 'FNR == 2 {print}' /tmp/combo)
C=$(awk 'FNR == 3 {print}' /tmp/combo)
D=$(awk 'FNR == 4 {print}' /tmp/combo)
sed 's/\t\t/\t@\t/g' /path/to/Events_today.txt \
| awk 'BEGIN {FS="\t";print "<?xml version=\"1.0\" encoding=\"UTF-8\"?>\n<kml xmlns=\"http://www.opengis.net/kml/2.2\">\n<Document>";} \
($11 >= LOW) && ($11 <= LOE) && ($10 <= LAN) && ($10 >= LAS) \
{print "<Placemark><name>"$1"</name><Point><coordinates>"$11","$10",0""</coordinates></Point></Placemark>"} \
END {print "</Document>\n</kml>"}' \
LAN=$A LAS=$B LOW=$C LOE=$D \
> ~/Desktop/new.kml
googleearth ~/Desktop/new.kml
rm /tmp/combo
The script asks for latitude and longitude lines to define a 'bounding box' on the Earth. After I've entered the four values in Zenity dialogs, Google Earth opens to show all the events in that bounding box, and each marker is labelled with the event's unique identifying number.
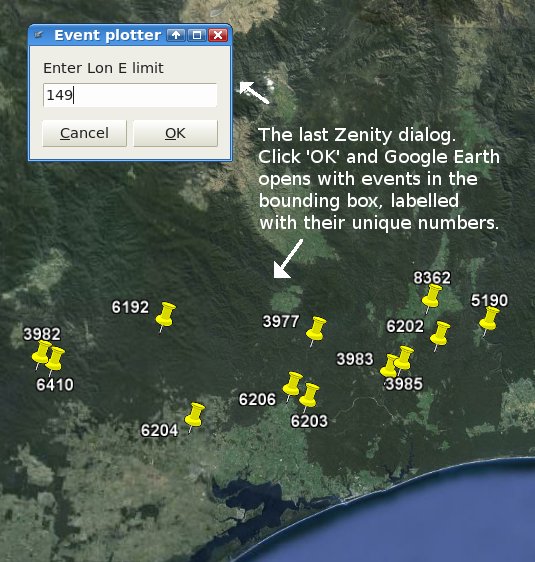
Mechanics: the first Zenity result is sent to a new file, /tmp/combo, and the succeeding three values are appended to that file as new lines. Four shell variables, A-D, are defined as what AWK finds when reading lines 1-4 in /tmp/combo. Next, sed fills any blank spaces between tabs with the dummy character @ in the table Events_today.txt; this is necessary to keep AWK straight on which field is which. [EDIT: This works in my table because only single blanks appear. A command to replace all blanks could be awk 'BEGIN {FS="\t";OFS="\t"} { for(i = 1; i <= NF; i++) { if(!$i) { $i = "@" } } print $0 }'] sed pipes the resulting table to AWK, which does two remarkable things. The BEGIN and END sections print the header and closing line of a basic KML file. The pattern-search section of the AWK command looks in Events_today.txt for records where the latitude (field 10) and longitude (field 11) values are in the bounding box, then prints from each record found a KML placemark line with the event's number as a label, and the actual latitude and longitude in their correct places. The final KML file is written to 'new.kml' on the desktop, Google Earth opens it, and /tmp/combo is deleted.
[The script uses the so-called 'pseudo-files' method of passing shell variables to AWK. There are other ways, but I like this one for its simplicity.]
This script works very fast. In actual use, an extension to this script pulls all the specimen data for the selected collecting events from another table and after a slight delay (programmed with the sleep command) opens those specimen records in a Gnumeric window over the Google Earth window.
#Another real example
I also use AWK for joining related tables. In the following shell script, Zenity asks for the name of a genus. Once entered, Gnumeric opens up with all the records for that genus from a table called Localities_today.txt, in which field 3 is the foreign key field corresponding to the primary key in Events_today.txt. Appended to each specimen record are the corresponding collecting events data.
#!/bin/bash
zenity --title="Full records" --entry --text="Enter genus name" > /tmp/name
grep $(cat /tmp/name) /path/to/Localities_today.txt > /tmp/records.txt
awk 'BEGIN {FS="\t"} {print $3}' /tmp/records.txt > /tmp/events.txt
touch /tmp/full.txt
for i in $(cat /tmp/events.txt)
do awk 'BEGIN {FS="\t"} $1==EVENT {print $0}' EVENT=$i /path/to/Events_today.txt >> /tmp/full.txt
done
paste /tmp/records.txt /tmp/full.txt > /tmp/joined.txt
sed '1i\Name_code Name Event_code Specimens Repository Reg_no Type_status ID_by Specimen_notes Record_source Mapping_note EventCode Locality_in_words State LatDS LatMS LatSS LongDE LongME LongSE Lat_DD_WGS84 Long_DD_WGS84 Unc Method Elev Day Month Year Collector CollNotes' /tmp/joined.txt > ~/Desktop/$(cat /tmp/name).txt
gnumeric ~/Desktop/$(cat /tmp/name).txt
rm /tmp/name /tmp/records.txt /tmp/events.txt /tmp/full.txt /tmp/joined.txt
The script generates a lot of temp files, but they're only included for debugging purposes, and so far the script hasn't failed me. The mechanics work like this:
The selected genus name is sent by Zenity to a temp file. grep retrieves that name using cat, searches all the specimen records for that name, and sends the 'N' records it finds to a temp file. AWK reads that file and pulls out the foreign key for collecting events from each record, and sends the list of 'N' foreign key values (one for each selected record) to a temp file. touch creates a temp file to hold the results of the next command. AWK reads the list of event values, and using a for loop, finds for each one the corresponding full event record. AWK then sends those 'N' full records to the temp file created by touch. Next, the paste command joins the 'N' selected specimen records and their corresponding 'N' selected event records, side by side in a line, separated by a tab (the default joiner for paste). sed adds a header line to the pasted-together file with field names separated by tabs, and sends the result to a new file named with the genus name entered into Zenity. Gnumeric opens that file, and rm deletes the temp files.
Note that grep is used to search the specimen records, not awk. The same script can be used to search the specimen records for any string, not just genus name. I also use this script to search for a species name, a museum name, a museum specimen registration number, etc.
#Very happy AWKer
I've now built a number of AWK shell scripts to query and join my tables in the ways I prefer, and they all work lightning-fast. They're way faster than the whole import/join/export procedure had been in Kexi or FileMaker Pro: a few seconds vs. 10-15 minutes. And no database is involved at all, since I work directly from my tables.
The odd angle to this story is that by moving to AWK and away from databases, I'd travelled back in time. the FileMaker Pro and SQLite I'd been using were from the 2000s, but grep, awk, paste and sed go back 30 years.
Oldies are truly goodies!
Learning AWK
Here's a series of three excellent tutorial articles that introduce AWK, from Dan Robbins of Gentoo Linux: