Have you ever wanted to split a spreadsheet into several spreadsheets according to the contents of a particular field? For example, you might have a music tracks spreadsheet with an 'artist name' field, and you want separate spreadsheets for each artist, with the usual field names along the top of each new spreadsheet.
You can split a spreadsheet by copying and pasting the different sections into new spreadsheets if there aren't many records. If there are lots of records, this manual approach can be pretty tiring. For splitting very large spreadsheets, most users turn to special stand-alone programs (in the Excel world) or fairly complicated macros (Excel, Open/LibreOffice Calc).
I split my spreadsheets using the GNU/Linux command line, as explained in this article. It's another of my trademark ugly hacks, but it works well and the command line steps can be combined into a script which runs fast and reliably.
#The overall plan
Here's a made-up example (screenshot 1): an accounts spreadsheet with records in date order. There are five different customers, and there are data in six fields for each record. What we're going to do is split this spreadsheet into five different spreadsheets, one for each customer.
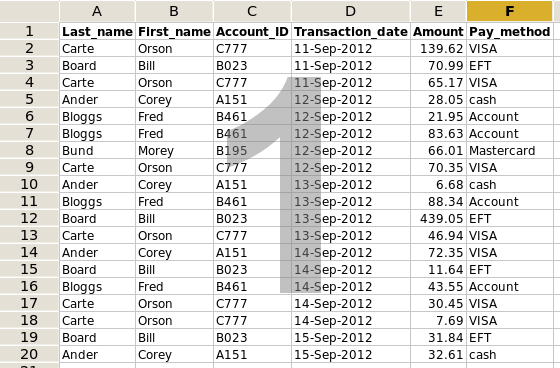
We'll do it by first sorting the spreadsheet by customer, then adding a flag in the sorted spreadsheet to show where the customer changes. We'll then convert the sorted and flagged spreadsheet to a text file, use text-editing commands to remove the flags, create one text file for each customer, add field names to those files and rename the files with the relevant customer's name. Each of those tabbed text files can then be opened in a spreadsheet program.
Now for a step-by-step explanation...
#Get the spreadsheet ready
1. Make a working copy of the original spreadsheet. We'll be doing the hack on the copy, not the original!
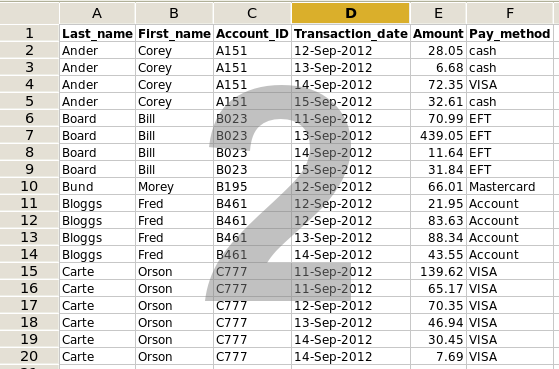
2. Sort the copy of the spreadsheet on the field of interest. As shown in screenshot 2, I've sorted the example on the Account_ID field, which is field D.
3. Add the flags. Insert a new column at the far left of the spreadsheet. In the top cell of the new column, enter the formula (screenshot 3)
=if(D1=D2,0,1)
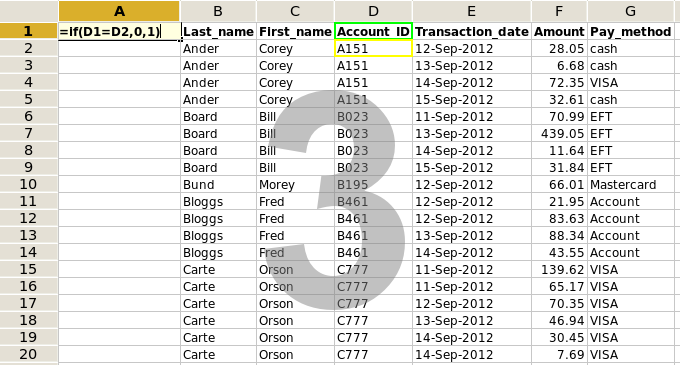
The formula means If the contents of cell D1 are the same as the contents of cell D2, put a '0' in the cell; if they're different, put a '1'. Copy this formula down to the bottom of the first column (screenshot 4).
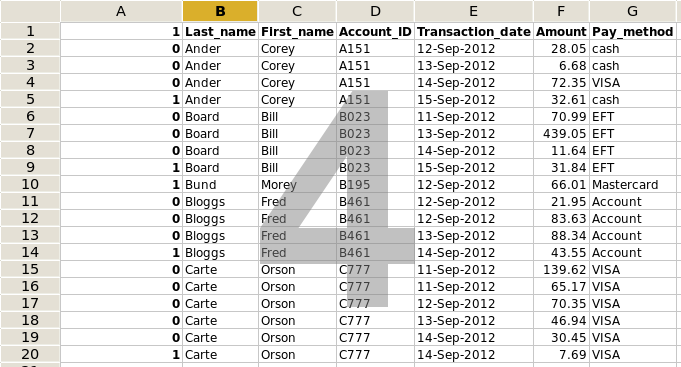
The '0's and '1's in the first column are flags. If you see a '0' at the left of a record, you know that the the customer in the next record down is the same. If you see a '1', the next record has a different customer.
Note that the last flag is a '1', because there's no customer at all in the next record. To simplify what we're going to do next, change that last '1' to a '0' (screenshot 5).
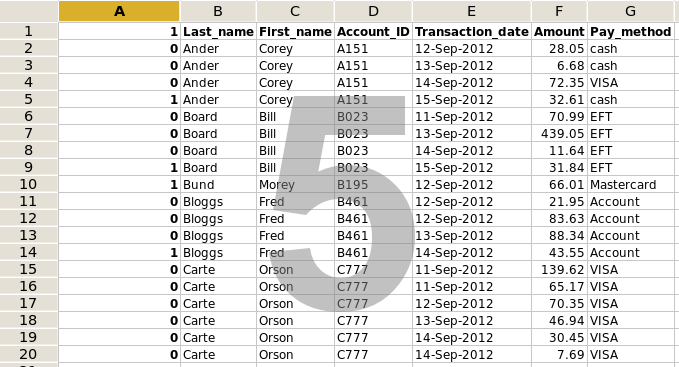
4. Save the spreadsheet as a tabbed text file (text with tabs) called sheet1.txt. The way you do this will depend on your spreadsheet program. The resulting text file is shown in screenshot 6.
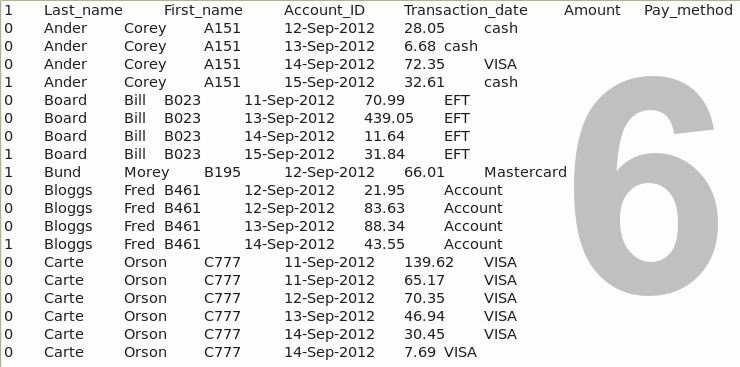
#Command line trickery
5. Open a terminal and navigate to the directory containing sheet1.txt. Enter the command
sed '/^1/a\break' sheet1.txt > sheet2.txt
Without going into the gory details of how the sed command works, what we've done here is create a new file, sheet2.txt, in which a line with the word 'break' has been inserted after each line beginning with a '1', as shown in screenshot 7.
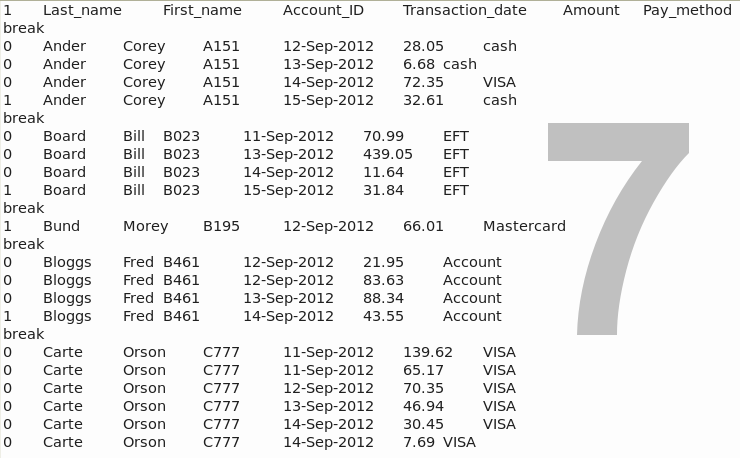
For an introduction to sed, see this excellent guide.
6. Trim off the flags. Enter the command
cut -f2- sheet2.txt > sheet3.txt
Here we've used the cut command to remove the '0' and '1' flags at the beginnings of lines and create sheet3.txt, shown in screenshot 8.
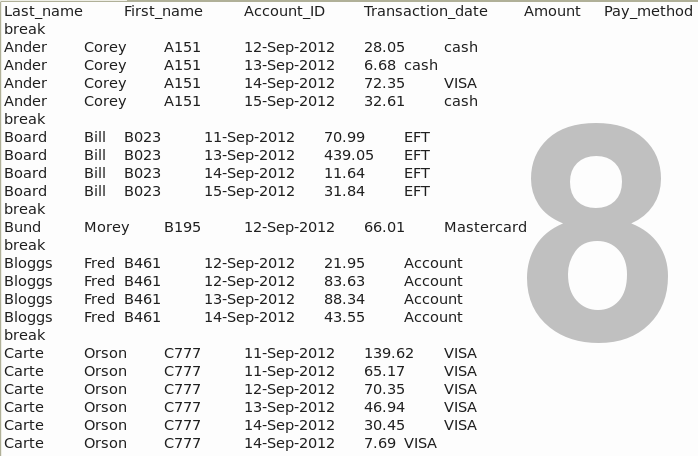
For more on cut, see its [Wikipedia entry](http://en.wikipedia.org/wiki/Cut%28Unix%29)_
7. Split the text file on 'break'. Enter the command
csplit -ks -b "%02d.txt" sheet3.txt /break/ {*}
Again ignoring details, we've used the csplit command here to split the text file just before the five lines with 'break' into six different files, as shown in screenshot 9. The first file, 'xx00.txt', contains the field names, while each of the remaining files has a single customer's records.
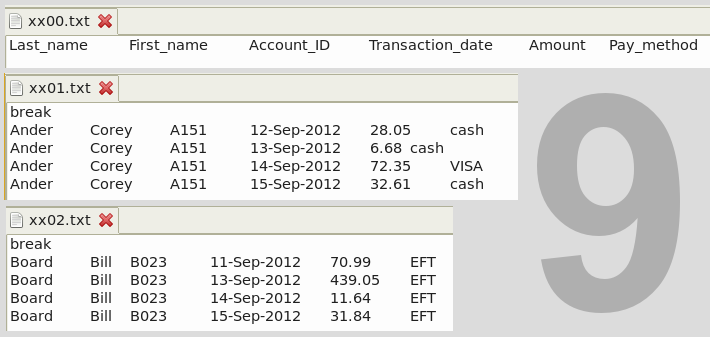
Note that csplit has a limit of 99 splits. If you have more than 99 different values (customer ID, music artist) in the field you've sorted, the last file will contain the remainder, unsplit. You can repeat the procedure on that last file after finishing the remaining steps (below) for the first split. For more on `csplit', see its GNU reference.
8. Replace 'break' with field names. Enter this ugly-looking command:
find . -type f -name 'xx*.txt' -exec sed -i 's/break/'"$(cat xx00.txt)"'/' {} \;
and you'll find that each of the files now has the field names in the first line, instead of 'break', as shown for xx01.txt - xx03.txt in screenshot 10.
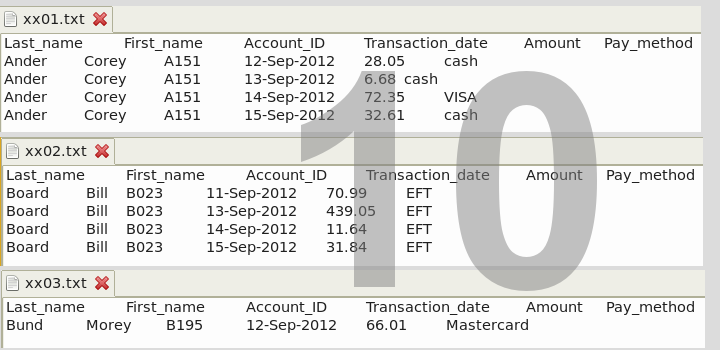
There are two commands at work here. The find command looks through the current folder for any .txt files with a name beginning with xx. These are the files that were generated by the csplit command. When find locates such a file, it executes the sed command, which substitutes for 'break' the contents of that first file, xx00.txt, containing the field names. The substitution doesn't happen in xx00.txt because 'break' doesn't appear there.
For more on the remarkably versatile find, see this tutorial.
9. Rename the new files with understandable file names. Enter this very ugly command:
for i in xx*.txt; do mv $i $(awk 'BEGIN {FS="\t"; OFS="_"} FNR==2 {print $1,$2}' $i).txt; done
This command uses a for loop to process files one by one. It looks for filenames of the kind 'xx(something).txt', and when it finds that file it renames it with the mv command. The mv command, in turn, uses the awk program to build the new filename from the contents of fields 1 (Lastname) and 2 (First_name) separated by an underscore (see screenshot 11). Because mv won't get a result from awk for _xx00.txt, containing the field names only, it deletes that file.
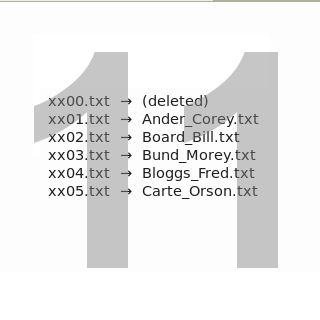
Instead of the customer name, I could have renamed the files using the data from the Account_ID field. In that case the command would have been
for i in xx*.txt; do mv $i $(awk 'BEGIN {FS="\t"} FNR==2 {print $3}' $i).txt; done
For good introductions to awk, see this webpage and this guide. 'About.com' has the basics of for loops, and the ancient mv command.
#Make it simpler, please!
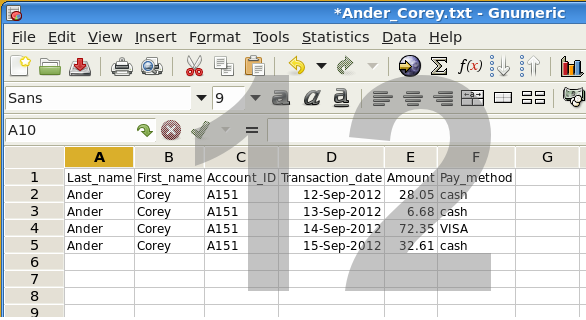
Each of the tabbed text files can now be imported into a spreadsheet program, as shown in screenshot 12, but it's not easy to remember all those commands, or to enter them correctly in a terminal!
To make the whole process simpler, the five commands we used after building sheet1.txt can be combined in a single script. As a final touch, we'll also delete sheet1.txt, sheet2.txt and sheet3.txt with the rm command. Here's the script:
#!/bin/bash
#Inserts 'break' after lines beginning with '1'
sed '/^1/a\break' sheet1.txt > sheet2.txt
#Cuts out flags at beginnings of lines
cut -f2- sheet2.txt > sheet3.txt
#Splits the text file into separate ones at the 'break' line
csplit -ks -b "%02d.txt" sheet3.txt /break/ {*}
#Replaces the leading 'break' line with field names
find . -type f -name 'xx*.txt' -exec sed -i 's/break/'"$(cat xx00.txt)"'/' {} \;
#Renames files with items from field contents
for i in xx*.txt; do mv $i $(awk 'BEGIN {FS="\t"; OFS="_"} FNR==2 {print $1,$2}' $i).txt; done
#Deletes sheet1.txt, sheet2.txt and sheet3.txt
rm sheet*.txt
I've saved this script as a text file called spreadsheet_splitter.sh and I've made the script executable.
Next time I want to split a spreadsheet like the one in our example, I first build sheet1.txt with steps 1 to 4, above. I then find sheet1.txt in my file manager, right-click it and browse under Open with for the script spreadsheet_splitter.sh. The act of opening sheet1.txt with the script generates the separate, correctly named text files and deletes sheet1.txt, all in a couple of seconds.
Which is a lot less time than it takes to explain how this works! The only modification of the script I need for different spreadsheets is to change the awk command to use particular items in the output text files for renaming.
The venerable rm command is discussed in Wikipedia. Two good introductions to bash scripting are at How-To Geek and The Linux Documentation Project.